Working with scala collections
Aug 16, 2015
One of the first things that makes people feel attracted to scala is its powerful collection’s library. For those developers coming from Java or C# backgrounds, having powerful collections at hand should not come as a surprise. But for others coming from C or PHP backgrounds it might open a world of possibilities that were not available to them before.
Immutability
For me, the cornerstone of scala collections is the fact that they are immutable. An immutable collection looks pretty much like any other collection, but the operations applied to them don’t change the original collection’s state but return a new collection instead:
// new immutable list with 4 elements
val myList = List(1, 2, 3, 4)
// append integer 5 to the list
val modifiedList = myList :+ 5
// size is 4
myList.size
// size is 5
modifiedList.sizeMethods on immutable collections are side effect free. You can always assume that their state won’t change at any given point in time during your program’s execution, which makes them simpler to work with and less error prone.
Scala works by default with immutable collections, but if you really need to work with mutable ones, you can also do so. You only need to import the mutable collection’s package:
import scala.collection.mutableStandard collections
The standard library comes with a good amount of collections, organized in the following hierarchy:
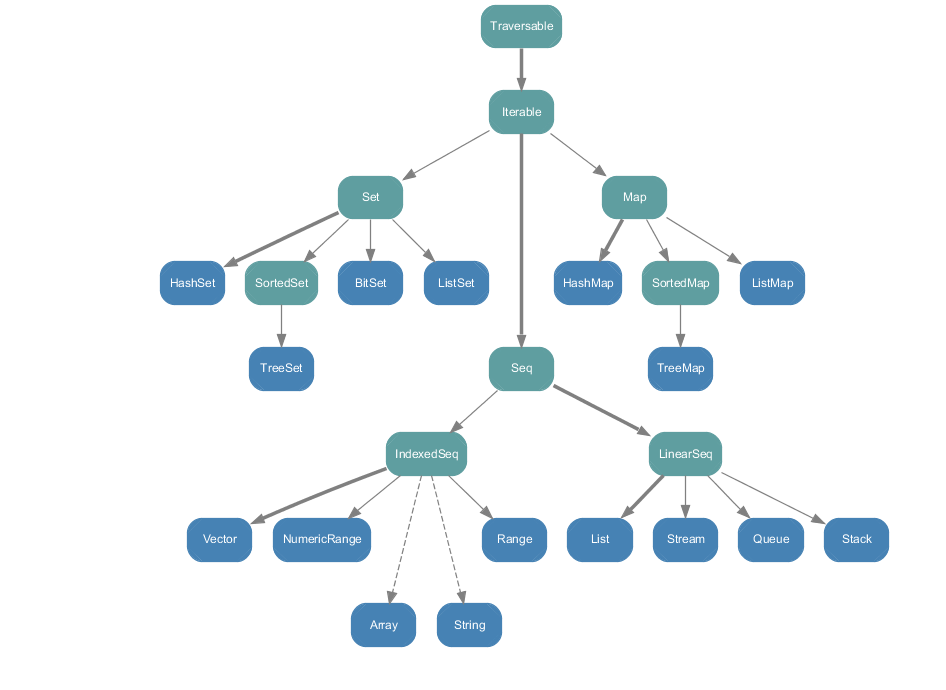
All of them inherit from Traversable and Iterable. This allows to loop through them using ‘foreach’ or with an iterator, to count their elements, to apply maps and reduces and all the other set of available functions.
Collection methods return the types that makes more sense to the operation applied to that collection. For instance, when operating on a List or a Set, we’ll get the same type when applying methods on them:
// flattening a list of lists results in a list
scala> List(List(1), List(2), List(3)).flatten
res0: List[Int] = List(1, 2, 3)
// flattening a set of sets results in a set
scala> Set(Set(1), Set(2), Set(3)).flatten
res1: scala.collection.immutable.Set[Int] = Set(1, 2, 3)
// the operation will result on the outer collection type
scala> List(Set(1), Set(2), Set(3)).flatten
res2: List[Int] = List(1, 2, 3)Conversions
What we just saw doesn’t mean that once you start working with one collection type you’re bound to it for life. You can convert from one type of collection to another using converters:
// from List to Set
scala> List(1, 2, 3, 4).toSet
res0: scala.collection.immutable.Set[Int] = Set(1, 2, 3, 4)
// from Map to List
scala> Map("a" -> 1, "b" -> 2).toList
res1: List[(String, Int)] = List((a,1), (b,2))
// not all conversions work straight away
scala> List(1, 2).toMap
<console>:8: error: Cannot prove that Int <:< (T, U).
List(1, 2).toMap
// but if we add the pairs to the keys...
scala> List((1, 1), (2, 2)).toMap
res2: scala.collection.immutable.Map[Int,Int] = Map(1 -> 1, 2 -> 2)Which one should I use?
I’ve met many developers who just fall in love with a single data structure and they use it always, everywhere. This actually defies the purpose of having such a rich collections library, since each of its types are better in certain scenarios and worse in others.
Sequences
The main properties of sequences is that they have a length and their elements’ positions are indexed. Within the Sequence trait there are two subtraits: LinearSeq and IndexedSeq. The former is more optimized towards operations over its head and tail, whereas the latter has better performance on apply and length.
This makes LinearSeq like Lists a better candidate for those algorithms that are going to process their elements accessing the head often, or prepending elements often. On the other hand, an IndexedSeq Vector might be better candidate if methods like apply are called often on the collection since its complexity is often O(1).
Sequences have a very interesting implementation of lazy lists, called Streams, which we’ll see in more detail later.
Sets
The most important characteristic of sets is that they do not contain duplicate elements. This property makes them ideal for those scenarios where it does not really matter how many times an element is in the collection, but only if it contains the element or not.
A very absurd scenario would be to determine if an article contains a given word:
val article = "This is a very interesting article about Scala collections. This article contains the word article several times."
//transforming a String to a Set without repeated words
def hasWord(w: String): Boolean = article.split(" ").toSet.contains(w)
scala> hasWord("article")
res0: Boolean = true
scala> hasWord("Java")
res1: Boolean = false
// given that String is also a collection, we could have done it directly, but this was just an illustrative example
scala> article.contains("article")
res2: Boolean = trueBeware!! There’s quite a big gotcha when dealing with very small Sets which I stomped on and could not figure out. Check this:
scala> val s1 = Set(1, 2, 3, 4, 5)
scala> val s2 = Set(5 ,4 ,3 ,2 ,1)
scala> s1 sameElements s2
res0: Boolean = trueAll seems to work just fine, right? The elements are inserted in different order to the Set but they are, at the end of the day, the same elements. Now look at this:
scala> val s1 = Set(1, 2, 3)
scala> val s2 = Set(3, 2, 1)
scala> s1 sameElements s2
res0: Boolean = falseWait, what!?
As it happens, the internal representation of a Set is one when it contains up to 4 elements and another one for 4 and more elements. As a result of that, the internal iterators used to make the comparison produce the elements in the order that they were originally added, hence failing the comparison.
Maps
The third collection trait is Map. The main property of maps is that they are represented using key - value pairs. This makes them very fast for lookups on known keys, pretty much like indexed sequences.
Typical scenarios where you’ll find maps are to represent countries and their capitals, train stations and the zone they are in, etc. In this example, we are mapping each floor of a building to their list of neighbours:
case class Neighbour(val name: String)
val building = Map(
"First Floor" -> List(Neighbour("Angela"), Neighbour("Mark")),
"Second Floor" -> List(Neighbour("Mikel"), Neighbour("Sara"),
"Penthouse" -> List(Neighbour("Pam"), Neighbour("Sandra"))
)
scala> building("Penthouse")
res0: List[Neighbour] = List(Neighbour(Pam), Neighbour(Sandra))Streams
Streams are a type of collection that I think deserve their own section.
A stream is basically a lazy list. Hence, they are part of the LinearSeq trait. The theory behind them tell us that the tail of a stream is only computed when needed. What this means in practice, is that you can have infinitely long Streams, such as a collection representing all natural or prime numbers.
It’s probably easier to understand with an example. Lets say that we want the first 10 natural numbers that are divisible by 7:
// we define a stream which contains all natural numbers
def naturals: Stream[Int] = {
def iterate(n: Int): Stream[Int] = n #:: iterate(n + 1)
iterate(0)
}
// then we simply pick the first 10 elements that are divisible by 7
scala> naturals filter (_ % 7 == 0) take 10 toList
res0: List[Int] = List(0, 7, 14, 21, 28, 35, 42, 49, 56, 63)Gosh this is powerful! With these techniques, it’s possible to do computations over absurdly large sets of data, or even upon theoretical sets of data. How cool is that?
The “trick” here is on the implementation of the cons operator. This operator is used to build Streams, concatenating its elements. The implementation goes like this:
// the list tail 't1' is a call by name parameter!
def cons[T](hd: T, t1: => Stream[T]) = new Stream[T] {
def isEmpty = false
def head = hd
def tail = tl
}Being the tail a call by name parameter, it does not get evaluated until it is actually accessed.
Performance
One always has to keep an eye on performance though. There is “danger” when using these collections naively. We need to be aware how to better traverse them to get the most out of them. For instance, in the previous example, in order to obtain the first 10 elements that are divisible by 7 from the naturals’ stream we’re iterating over the stream one by one and applying a check on each of them, only selecting those that are divisible by 7.
That means that we’re going to go through 64 elements before being done.
If we think on the relationship between natural numbers and the property of “being divisible by”, we can reach the same result as before if we multiply each natural number by the number that we’re looking to be divisible for, in this case 7.
scala> naturals map (_ * 7) take 10 toList
res0: List[Int] = List(0, 7, 14, 21, 28, 35, 42, 49, 56, 63)This will result on a quicker execution, since only the first 10 elements of the naturals’ stream will be evaluated in order to yield the expected result.
Wrapping up
In summary. I like the scala collection’s library a lot. I think it is both powerful and with well designed APIs.
I also think it is important to understand what each collection is meant for, and also it doesn’t hurt to dig deeper into their implementations to know both how they are built and their limitations.
I’m now trying to come up with a small enough sized project to put all these collections at a good use and explore them further. I’ll keep you posted!
Tweet